Dutch Interoperability Network
Bridging Data, Disciplines, and People

The Dutch Interoperability Network (DIN) is a growing community of practice that builds on Open Science NL’s investment in local and thematic Digital Competence Centres, particularly its focus on open research software and research data interoperability. By bringing together expertise from diverse disciplines, the network focuses on sharing knowledge and co-developing materials to support both new and experienced professionals by highlighting best practices and practical ways to embed interoperability into everyday research workflows.
We host monthly meetings where our members exchange ideas and lay the groundwork for what we hope will become a sustainable and collaborative network. Current priorities include developing accessible starting materials, supporting peer learning and organizing workshops to foster ongoing dialogue and strengthen the interoperability community.
Join the Dutch Interoperability Network
DIN is open to everyone working on interoperability in research data, digital infrastructure, metadata, vocabularies, standards, tools, community building or related interoperability practices.
What the DIN does
- Organizes monthly community meetings focused on interoperability topics
- Raises awareness of interoperability challenges and opportunities
- Facilitates exchange of experiences, tools, and approaches across domains
- Supports alignment between national initiatives and infrastructures
- Contributes to developing training and capacity-building activities
- Participates in events to advertise interoperability across domains
- Promotes collaboration within and between organisations
Background
Interoperability connects systems, datasets, and disciplines so that research data can be shared, accessed, understood, and reused meaningfully. It is also a core pillar of the FAIR principles, which aim to ensure that research data is Findable, Accessible, Interoperable, and Reusable.
Despite growing awareness of interoperability in the research and data management communities, several misconceptions still hinder its effective implementation in everyday research practices. These include assumptions such as:
- Common file formats (like CSV or JSON) alone ensure interoperability, without addressing semantic alignment;
- Interoperability can be postponed to later stages, resulting in costly retrofitting;
- It only applies to large-scale collaborations, and not to smaller or individual research projects;
- Adopting standards alone is sufficient, without ensuring shared interpretation and consistent implementation.
As a result, interoperability is often seen as a technical add-on rather than an enabler of collaboration, reproducibility, and impact.
In reality, interoperability is far more complex than it appears. Achieving it requires addressing semantic, syntactic, technical, organizational and legal challenges.
- Semantic standards support consistent interpretation across systems by using shared vocabularies, metadata, and domain-specific ontologies, which are especially important in interdisciplinary research where terms often have different meanings.
- Meanwhile, technical and syntactic standards ensure smooth data exchange between systems through aligned formats, communication protocols and validation tools.
- Equally important are organizational and legal frameworks, which provide the trust and governance needed to responsibly share data and handle sensitive information via data policies, intellectual property rights, licensing, and privacy regulations.
Many of these challenges can be mitigated early by integrating appropriate standards and structured data workflows into everyday research practices, leading to more efficient, reliable, and reusable research that complies with open science policies while enhancing visibility and societal impact.
Achieving this, however, is not just about systems; it’s about people working together. Collaboration between researchers, data stewards, and institutions is essential. Key enablers include: knowledge sharing, co-designing data workflows from the outset, aligning institutional data support services with the research lifecycle, and recognizing data stewardship in professional frameworks.
These efforts can be supported by practical tools such as discipline-specific metadata templates, which reduce workload and promote consistent practices across research teams.
Resources & Outputs

DIN uses Zenodo to share training materials (PDFs, datasets), use cases (formal outputs), reports and deliverables.

Interoperability Challenges and Recommendations Across SSH, LSH, and NES. Summary of feedback received by TDCCs at the Open Science Festival 2025, Groningen.
Events
Come talk to us during these upcoming events:
19 May 2026 in Hilversum
Members of the DIN will be present throughout the day at this event. Please find us at the DIN booth, or join our open discussion session Exploring Interoperability by Connecting People, Data and Systems.

Connecting Knowledge: Tackling Interoperability in Research
21 May 2026 in Utrecht
This TDCC-event brings together national initiatives, researchers, and support professionals. Members of the DIN will be present at this event and will contribute to parallel breakout sessions.

National Onboarding Day on Research Software Management & Interoperability
4 June 2026 in Utrecht
Members of the DIN will be present at this event and contribute to discussions across communities and will present about the DIN during the afternoon interoperability track.
Contacts at the TDCC
If you are a researcher in the Netherlands and you need support regarding interoperability, reach out to the TDCC Interoperability Staff:
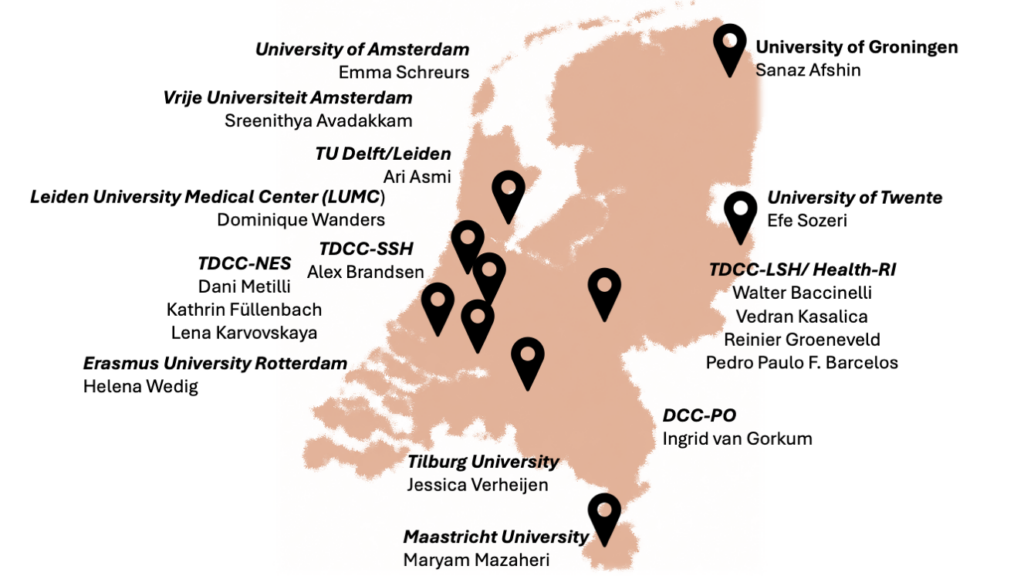
Members of the network
Sanaz Afshin Interoperability community manager at the University of Groningen
Ari Asmi Interoperability community manager at Leiden Universiteit and TU Delft library
Sreenithya Avadakkam Interoperability Community Manager and Trainer at Vrije Universiteit Amsterdam
Pedro Paulo F. Barcelos Semantics & Metadata Specialist at Health-RI
Ingrid van Gorkum Interoperability community manager at DCC-PO
Reinier Groeneveld, Semantics & Metadata Specialist at Health-RI
Lena Karvovskaya Community Coordinator at TDCC-NES
Maryam Mazaheri Product Owner Linked Data and Community Manager Interoperability at University Library Maastricht
Emma Schreurs Interoperability community manager at the University of Amsterdam
Efe Sozeri Interoperability community manager at Universiteit Twente
Jessica Verheijen Interoperability community manager at Tilburg University
Dominique Wanders Community manager at LUMC
Helena Wedig Research Software and Interoperability Training Lead at Erasmus University Rotterdam