
When Chemistry Speaks the Same Language: The Role of Ontologies
Reflections from the 4th Ontologies4Chem Workshop
by Dr. Sreenithya Avadakkam, Interoperability Community Manager and Trainer, Vrije Universiteit Amsterdam
As an interoperability community manager at Vrije Universiteit Amsterdam, I spend a lot of my time thinking about one deceptively simple question: how can we make research data truly interoperable and reusable by other researchers? It sounds straightforward. In practice, it is one of the biggest challenges in modern science.
The Problem with Chemistry Data
Coming from a computational chemistry background, I have seen how difficult it can be to reuse data from other labs or publications. Data arrives as PDFs, spreadsheets, or Word files, each with its own format, its own terminology, and its own assumptions about what the reader already knows. A reaction yield reported in one paper might omit the solvent, temperature, or catalyst loading that a colleague in another lab would consider essential. An experiment might be impossible to reproduce not because the science was wrong, but because the metadata, in other words the context, was missing. And even when code exists to automate computational workflows, it often cannot be understood or reused by others because the documentation simply is not there.
Chemistry does follow many standard practices, of course. The periodic table organises elements by their properties. IUPAC naming conventions give molecules consistent names. SI units mean that a gram is a gram everywhere. But these standards only go so far. The moment you need to describe a reaction including its conditions, yield, side products, and equipment, the shared language starts to break down. Every lab, every group, every database tends to do it slightly differently.
You might reasonably ask: is some variation not inevitable? Chemistry has a staggering diversity of data types: molecules, reactions, spectra, crystallographic data, computational simulations, biological assays, and more. Data is generated by hundreds of thousands of independent labs with different equipment, different research questions, and conventions built up over decades. Fields like astronomy and bioinformatics are often held up as examples of good data interoperability, but it is worth remembering that it took decades of sustained community effort, and it remains ongoing. Chemistry has been building that same foundation, and the pace is accelerating.
So what can be done? A promising starting point is to develop a structured, shared language for describing chemical data, one that both humans and computers can understand. This is where ontologies come in.



The beautiful old town of Limburg an der Lahn, host city of the 4th Ontologies4Chem workshop.
What Is an Ontology, Really?
The word “ontology” sounds complex, but the idea behind it is intuitive. An ontology is essentially a structured vocabulary. It is a formal model that describes concepts and relationships among them.
Think of it like this: a regular dictionary tells you what a word means. An ontology goes further: it also tells you how that concept relates to others. In chemistry, an ontology might define not just what a “reaction” is, but also that a reaction has reactants, produces products, takes place under certain conditions, and can be classified by the type of bonds that break or form. It is designed so that both humans and computers understand information in the same way.
This matters enormously for data sharing. When two datasets use the same ontological terms, software can automatically compare them, combine them, and search across them without a human having to manually figure out what each file means. Ontologies help standardise terms, connect related data, enable semantic search and reasoning, and support the FAIR principles: making data Findable, Accessible, Interoperable, and Reusable.
The Landscape of Ontologies in Chemistry
Efforts to structure chemical data go back to the late 1990s, when researchers began exploring machine-readable formats for the early Semantic Web. One important early development was the Chemical Markup Language (CML), created by Peter Murray-Rust and Henry Rzepa. CML introduced a standard for encoding molecules, reactions, spectra, and crystallographic data in a structured way, and promoted key ideas such as persistent identifiers and controlled vocabularies. As the Web Ontology Language (OWL) matured in the 2000s, chemistry moved toward more expressive, logic-based representations. A major milestone was ChEBI (Chemical Entities of Biological Interest), a carefully curated ontology of chemical entities that remains widely used in the life sciences today.
Not all ontologies work at the same level of detail. It helps to think of them in three layers, from the most abstract to the most specific.
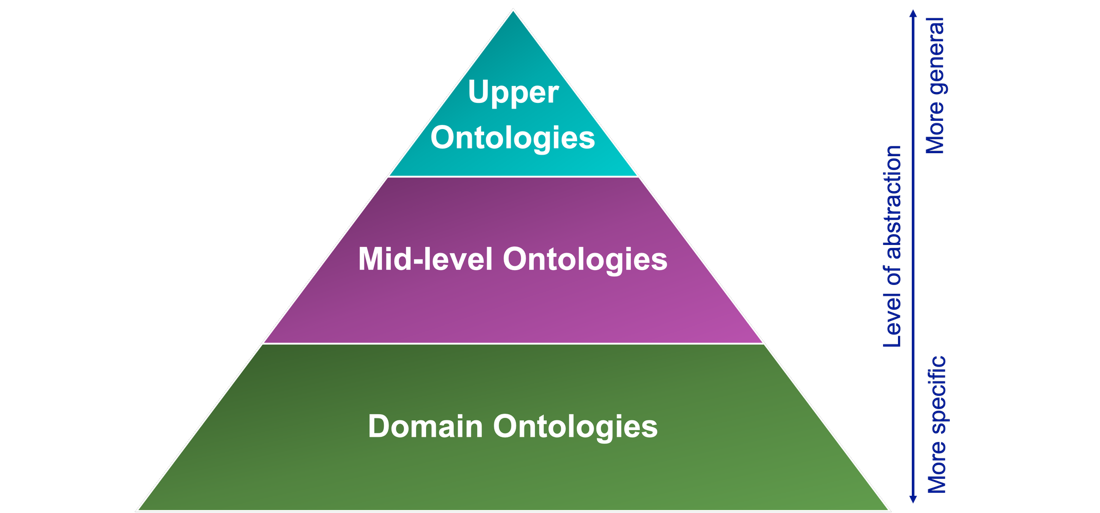
Upper ontologies define highly abstract, domain-independent categories that apply across all domains of science, such as what counts as an object (something that persists over time, like an atom), a process (something that happens over time, like a reaction), a quality (a measurable property, like temperature) or a relation (how one entity participates in or is part of another). Examples include BFO (Basic Formal Ontology) and SIO (Semanticscience Integrated Ontology). They provide the philosophical scaffolding on which more specific ontologies are built.
Mid-level (reference) ontologies provide reusable models for broadly applicable concepts like units of measurement, or relationships such as “is part of” and “participates in.” The Relation Ontology (RO) and the Ontology for Biomedical Investigations (OBI) are examples. They act as shared building blocks that domain-specific ontologies can draw from.
Domain ontologies capture detailed, domain-specific knowledge, such as the concepts and rules of chemistry. These are the ontologies a researcher would actually use day to day to describe compounds, reactions, materials, and measurements. The key domain ontologies in chemistry are provided in Table 1 below.
Table 1. Key Domain Ontologies Used in Chemistry Research
| Chemistry Domain | Ontology | Description |
|---|---|---|
| Chemical compounds | ChEBI, ChemOnt | What a molecule is, how it is classified, and how it relates to other molecules |
| Chemical reactions | RXNO, MOP, OntoRXN | The types of reactions molecules undergo and the mechanisms behind them |
| Laboratory methods | CHMO | The experimental techniques used to measure and analyse chemical samples from NMR to chromatography |
| Process chemistry | PROCO, OntoCAPE | How reactions are scaled up from lab bench to industrial production |
| Molecular properties | CHEMINF | The computed and measured descriptors used to characterise molecules such as molecular weight, charge, structure fingerprints |
| Computational chemistry | OntoCompChem | The outputs of quantum chemistry and molecular simulation calculations |
A Trip to Limburg
To understand how ontologies are being developed and used in chemistry right now, I travelled to the 4th Ontologies4Chem workshop, organised by NFDI4Chem in collaboration with NFDI4Cat, Beilstein-Institut, and the Physical Sciences Data Infrastructure (PSDI). It was held from 11-13 November 2025 in the historic town of Limburg an der Lahn in Germany, a beautiful place of timber-framed houses, a hilltop castle, and a cathedral overlooking the old town. With support from the Thematic Digital Competence Centre for the Natural & Engineering Sciences (TDCC-NES), I joined researchers who are building the ontologies, tools, and services that could help chemistry data become truly interoperable.
I am not an ontology expert. But that is partly what made this workshop so valuable. It was a rare opportunity to sit alongside the people building these systems and ask: what problem are you solving, and why does it matter? What follows is an overview of the ideas, discussions, tools, and services shaping the future of semantic chemistry without getting deep into technical detail.

What the Workshop Revealed
1. Making Data Findable Across Borders
One of the persistent frustrations in research is that data exists somewhere but cannot be found or combined with other data because each database speaks its own language. Several presentations at the workshop addressed this directly.
Physical Sciences Data Infrastructure (PSDI) is a UK initiative that brings together data from across the physical sciences including crystallography, materials, computational chemistry, and more, into a single connected infrastructure. It brings existing specialised resources such as crystal-structure databases (CCDC), materials and chemical-property data (NOMAD), and biomolecular simulation repositories under one roof. It offers cross-database search, file-format conversion, and tools for digitising old lab-notebook data. The goal is to make it easier for researchers to find, access, and reuse data across disciplines, enabling interdisciplinary collaborations that siloed databases simply cannot support. Aileen Day, who presented PSDI, described metadata as the “glue” connecting datasets, tools, and workflows. The team is actively working on making the platform more accessible and welcomes community feedback. Slides from Aileen Day’s presentation on PSDI.
Terminology Services 4 NFDI (TS4NFDI) acts as a central vocabulary hub within the German National Research Data Infrastructure (NFDI). It provides access to controlled vocabularies and ontologies from chemistry, physics, life sciences, engineering, and the social sciences. It also offers tools to manage, align, and map terminology across disciplines, making it much easier to combine and compare data from different research communities. Slides from the TS4NFDI presentation.
The Ontology Lookup Service (OLS), hosted by the European Bioinformatics Institute (EMBL-EBI), offers a practical starting point for researchers who want to explore existing ontologies. It provides a single place to search biomedical and life-science ontologies, explore term definitions and relationships, and integrate ontologies into your own workflows.
2. The Metadata Standard for Chemical Datasets
If you have ever tried to share a dataset across European research portals, you may have encountered DCAT-AP. It is a standard for describing public-sector datasets in a consistent way so that other systems can discover and understand them automatically.
Philip Strömert and Hendrik Borgelt presented ChemDCAT-AP, an extension of this standard tailored specifically for chemistry and catalysis. It adds richer, domain-specific metadata fields so researchers can describe chemical datasets with the precision the field requires. It is modular, reusable across disciplines, and designed to be easy to extend, which is a promising sign that the community is building for longevity rather than just the immediate problem.
3. Automating the Lab Notebook
A presentation from Mark Doerr demonstrated LARAsuite, a suite of tools designed to automate data and metadata capture directly from laboratory devices. Rather than relying on researchers to manually record experimental details (a process notorious for inconsistency and omission), LARAsuite connects to instruments through a standardised communication protocol and enriches the collected data with ontology-based meaning. The result is data that is machine-readable and searchable from the moment it is generated.
Mark highlighted that ontologies are particularly powerful in use cases like drug development and enzyme catalysis, where consistently recording reaction conditions such as solvents, temperatures, and catalysts is essential for comparing results across experiments. He also argued for using small, modular “micro-ontologies” that are easier to maintain and keep logically consistent.
4. The Long Game: Building Interoperability Across Systems
MADICES is a community effort focused on creating guidelines and standards for data interoperability across the chemical sciences. Samantha Pearman-Kanza shared updates from the third MADICES workshop, which focused on practical challenges such as how electronic lab notebooks, data repositories, and analysis software can exchange information more smoothly. The key message was sobering but realistic: this is a long-term project with no quick fixes. The long-term benefits namely reproducible science, reusable data, and trustworthy results make the sustained effort worthwhile.
5. Managing Research Data End to End
DataPLANT is the German national research data consortium for plant science, providing a user-friendly infrastructure and services for managing complex research data. At the heart of their infrastructure is the Annotated Research Context (ARC), a structured container that captures not just raw data but also metadata, protocols, workflows, instruments, and provenance. ARCs are packaged as RO-Crates, a lightweight standard for sharing research data with all its context intact. The result is something like a complete, citable research object: everything another scientist would need to understand, reproduce, and build on your work. The platform supports researchers across subfields like genomics, metabolomics, and proteomics, helping them transform complex experiments into clean, well-documented, shareable packages.
6. Classifying Molecules at Scale
Several presentations focused on the challenge of chemical classification: determining what kind of molecule something is, and doing so consistently across millions of compounds.
ChemLog approaches chemical classification using formal logic. Rather than relying on rules of thumb, it uses a type of mathematical logic capable of describing complex molecular features such as atom connections, functional groups, and substructures in a precise, computable way. It is especially useful for curators working with large databases like ChEBI or PubChem, where manually classifying millions of molecules one by one would take too long.
Chebifier 2 takes a complementary approach: instead of using one method, it combines rule-based logic, machine learning, and large language models into an ensemble. Each method contributes its strengths: rules are transparent and reliable, machine learning scales well to large datasets, and language models handle complex or ambiguous cases. Together, they can classify molecules into more than 1,700 ChEBI categories. It is a good example of how AI is becoming a practical tool for ontology work, not just a theoretical promise. Slides from the molecular classification session.
7. Reactions and Biochemistry
Two presentations focused specifically on chemical reactions, an area where the challenge of consistent description is especially acute.
Rhea is a curated database of biochemical and transport reactions. It uses ChEBI identifiers to describe the participants in each reaction and supports sophisticated queries through a SPARQL endpoint, which is a way of asking complex questions across linked databases using a standardised query language. Rhea is the standard for annotating reactions in UniProtKB, the major protein sequence and function database. For researchers in biochemistry or metabolomics, it is an increasingly important resource for linking chemical reactions to proteins, pathways, and genomic data.
React4Cat is a newer tool aimed at catalysis research, where experiments frequently produce unwanted side reactions that make dataset classification difficult. It helps by automatically comparing experimental data with established reaction databases and classifying reactions based on their chemical features. It is a small but meaningful step toward making catalysis data more reusable.
8. A Vision for the Future of Chemical Knowledge
An ambitious presentation came from Chris Mungall, who introduced CHEMROF. It is a semantic framework designed to bring structure and consistency to how chemical knowledge is represented across the entire field. CHEMROF acts as both a standard data model and a high-level blueprint for improving large ontologies like ChEBI. It provides clear design patterns for describing atoms, molecules, salts, mixtures, and reactions in a way that connects naturally to other scientific domains.
Chris also described a vision for a more open, modular future version of ChEBI built on CHEMROF, and the role that AI-assisted curation tools could play in developing and maintaining these resources over time. It was a reminder that ontologies are not static documents. They are living resources, and the community is actively rethinking how they should be structured for the next generation of research.

What Holds Us Back and What Moves Us Forward
The workshop was candid about the challenges that remain. Ontology fatigue is real: researchers are often confronted with dozens of overlapping or competing ontologies, and it is not always clear which one to use or trust. The steep learning curve means that most researchers have never been taught how to apply ontologies to their data, even when the tools exist. Fragmented data, spread across incompatible repositories in incompatible formats, remains the norm. And many ontologies still have gaps; areas of chemistry where no adequate representation yet exists.
The responses to these challenges, emerging from work across the community, tend to converge on a few principles: reuse and build on existing ontologies rather than starting from scratch; invest in better tooling that makes ontologies accessible to non-specialists; develop semantic metadata standards that work across disciplines; and above all, treat interoperability as a community effort rather than something any single lab or project can achieve alone.
Why It Matters
Open Science NL has recently launched a national effort in the Netherlands to strengthen interoperability skills among researchers. The goal is not to turn every researcher into an ontology engineer, but rather, to build enough shared infrastructure, including vocabularies, standards, and tools so that sharing and reusing data becomes the path of least resistance. A starter resource, Interoperability in Research Contexts, developed collaboratively by interoperability community managers across the country together with the Dutch Interoperability Network, is a sign that this work is gaining institutional momentum.
The workshop in Limburg showed that the chemistry community is moving in this direction. There is a vibrant international community working on these problems, from the most abstract questions of how to formally represent chemical knowledge, to the most practical questions of how to get a lab instrument to record its own metadata correctly. A new edition of the workshop is already planned for November 2026.
Chemistry has always been a discipline built on shared language, including the periodic table, IUPAC names, SI units. Ontologies are simply the next chapter of that story: a shared language for the digital age, built not just for humans, but also for the machines that help us do science.
This blog post was reviewed and edited by the ontology engineers Kathrin Füllenbach and Dani Metilli, TDCC-NES. The Interoperability in Research Contexts starter resource is available at https://doi.org/10.5281/zenodo.17566838.
Get Free Ontology Support
If you are a researcher in one of the natural and engineering sciences disciplines and need support to adopt ontologies in your research, or have suggestions or ideas about how to improve ontology implementation in the Netherlands, reach out to the DCC-NES Ontology Engineers!


